
智能无损网络 - 华为
定义
智能无损网络是基于PFC优先级流控机制,结合智能化拥塞控制技术,使以太网满足分布式高性能应用无丢包、低时延、高吞吐诉求的能力。
本文档介绍了智能无损网络的配置,具体包括PFC优先级流量控制、无损队列的缓存空间优化、无损队列的动态ECN门限、无损队列的AI ECN门限、快速ECN拥塞标记、快速CNP拥塞通知、无损队列的大小流区分调度、动态负载分担和网算一体。
目的
随着全球企业数字化转型的加速进行,数据中心的使命正在从聚焦业务快速发放向聚焦数据高效处理进行转变。为了提升数据处理的效率,HPC高性能计算、分布式存储、AI人工智能等当今热门应用要求数据中心网络具有无丢包、低时延、高吞吐的能力。然而传统的基于TCP/IP协议栈的网络通信由于在数据拷贝等关键环节资源消耗较大并且时延过高,无法满足对网络性能的高要求。
RDMA(Remote Direct Memory Access,远程直接内存访问功能)利用相关的硬件和网络技术,使服务器的网卡之间可以直接读内存,最终达到高带宽、低时延和低资源消耗率的效果。但是RDMA专用的InfiniBand网络架构封闭,无法兼容现网,使用成本较高。RoCE(RDMA over Converged Ethernet)技术的出现有效解决了这些难题。RoCE即使用以太网承载RDMA的网络协议,有两个版本:RoCEv1是一种链路层协议,不同广播域下无法使用;RoCEv2是一种网络层协议,可以实现路由功能。
当前高性能计算、分布式存储、人工智能等应用均采用RoCEv2协议来降低CPU的处理和时延,提升应用的性能。然而,由于RDMA的提出之初是承载在无损的InfiniBand网络中,RoCEv2协议缺乏完善的丢包保护机制,对于网络丢包异常敏感。同时,这些分布式高性能应用的特征是多对一通信的Incast流量模型,对于以太交换机,Incast流量易造成交换机内部队列缓存的瞬时突发拥塞甚至丢包,带来应用时延的增加和吞吐的下降,从而损害分布式应用的性能。
智能无损网络基于PFC机制提供了智能化拥塞控制技术,可以解决传统以太网络拥塞丢包、时延大的约束,为RoCEv2分布式应用提供“无丢包、低时延、高吞吐”的网络环境,满足分布式应用的高性能需求。
优化队列缓存空间,尽量确保无损队列不丢包
根据芯片的转发能力合理划分各缓存空间,最大程度上保证在触发PFC流控之前无损队列的不丢包转发。
动态调整ECN门限,平衡无损队列的低时延与高吞吐
依据流量的Incast并发程度、大小流占比,动态调整无损队列ECN拥塞标记的门限,平衡队列的低时延与高吞吐。与优化队列缓存空间结合,尽量在触发PFC流控之前先触发ECN门限缓解拥塞。
根据AI算法,智能调整无损队列的ECN门限
通过AI算法,设备可以识别流量模型,从而可以根据不同的流量场景智能的为无损队列设置最佳的ECN门限,保障业务无丢包下的低时延和高吞吐,使业务性能达到最佳。
快速ECN拥塞标记,缩短拥塞通知时间
在队列遇到拥塞时,对出队列的报文进行ECN拥塞标记,从而缩短了从设备给报文打上ECN标记到设备将携带ECN标记的报文转发出去所经历的时间,即缩短了拥塞通知时间。
快速CNP拥塞通知,及时调整源端流速
转发设备在遇到拥塞时,代替目的服务器向源端服务器发送CNP拥塞通知报文,以及时调整源端服务器的发包速率,缓解转发设备队列缓存的拥塞。
识别大流与小流,保障无损队列小流转发时延
对无损队列中的大小流进行识别,优先调度小流的报文,从而保障小流的转发时延。
动态负载均衡,选择拥塞最轻的链路转发报文
多路径场景下,度量各个链路的拥塞状态,选择拥塞最轻的链路转发报文。
网算一体,提升HPC小字节报文场景计算效率
HPC小字节报文场景下,通过网络设备对服务器集合通信的部分内容进行计算,减少服务器集群间的通信量,从而降低HPC网络时延,提升计算效率。
智能无损网络应用场景
组网描述
如图3-1所示,为数据中心网络的物理网络单元PoD的典型组网,PoD内部署了一个Spine-Leaf网络,Leaf和Spine之间采用100GE链路全互联。根据实际部署的应用,服务器使用25GE或100GE接入Leaf交换机,支持M-LAG双归接入。服务器集群上部署了RoCEv2分布式高性能应用,为了保障应用的性能,需要在PoD内为RoCEv2流量提供低时延、无丢包、高吞吐的环境。此时可以在PoD的交换机上部署智能无损网络技术,通过智能化的网络拥塞控制满足RoCEv2应用的需求。
图3-1 智能无损网络的应用组网图
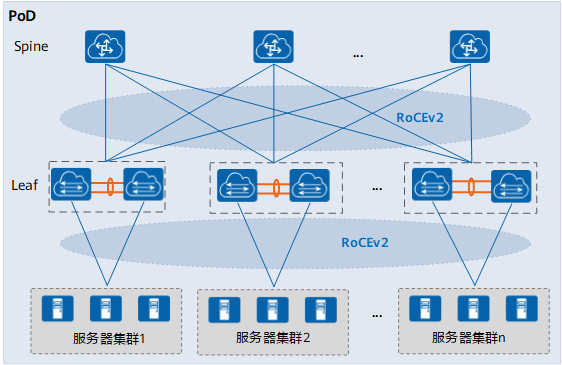
由于智能无损网络是针对RoCEv2流量的拥塞控制,服务器上实际部署的应用不同,网络中的流量模型也不同,相应的智能无损网络技术也需要进行智能化调整。比如网络中流量呈现Incast模型时,需重点保障无拥塞丢包;大流较多时,需保障大数据传输的高带宽、高吞吐;对于时延敏感型小流,需保障极低的时延。总体来说,智能无损网络目前主要应用于以下业务场景。
场景描述
高性能计算场景-HPC
HPC是高性能计算机群的简称,构建高性能计算系统的主要目的就是提高运算速度,要达到每秒万亿次级的计算速度。这类机群主要解决大规模科学问题的计算和海量数据的处理,如科学研究、气象预报、计算模拟、军事研究、生物制药、基因测序、图像处理等等。场景上主要有以下特点:
- HPC并行计算把单个任务拆分为多个子任务并行处理,来提高计算效率,因此随着服务器计算能力不断提升,网络性能的压力也随之加大,计算节点间的通信等待时间占任务总时长比重过高,影响并行计算总的任务完成时间。智能无损网络技术可以重点保障HPC场景的低时延效果,降低任务完成时的通信等待时间。
- HPC并行计算时,由于服务器工作模式基本类似,流量模型大多为“N对N”;每次任务同步结果时,流量模型是“N对1”的 Incast流量。
- HPC场景大多使用CPU芯片进行计算,服务器规模较大,通常使用100GE接入Leaf交换机,由于更注重低时延的效果,可以采用单归接入。
分布式存储场景
传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,将数据分散存储在多台独立的设备上,利用多台存储服务器分担存储负荷。场景上主要有以下特点:
- 分布式存储里,一个文件分发到多个服务器的存储,以进行文件的读写加速和冗余备份。随着存储性能不断提升,网络压力也随之加大,影响分布式存储系统吞吐性能的提升,智能无损网络需要重点保障分布式存储场景的高吞吐效果。
- 应用将原始和备份数据写入多个服务器时,会造成“1对N”的Incast流量;应用请求读取文件时,会并发访问多个服务器的不同数据部分,每次读取数据汇聚到交换机时的流量模型为“N对1”的Incast流量。
- 由于业界在分布式存储系统中大多采用标准字节的流量进行通信,所以网络中相同大小的流量较多。
- 分布式存储系统内会分为计算和存储节点,节点数量按业务需要部署,通常情况下计算和存储的节点数量按3:1比例部署。存储性能主要依赖于NVMe固态硬盘,对计算性能的要求不高,服务器规模在几十到几千不等,一般使用25GE接入Leaf交换机,为了保障吞吐性能,建议采用M-LAG双归接入。
人工智能场景-分布式AI训练
AI(Artificial Intelligence,人工智能),是研究、开发用于模拟、延伸和扩展人的智能的技术科学。AI应用包括机器人、语音识别、图片识别、自动驾驶、智能推荐等。AI中最重要的就是深度学习算法,深度学习算法是计算密集的迭代式浮点运算,通过多层的神经网络对大量样本进行特性提取,并通过参数不断的调整、不断学习,先训练,后推理。为了提高深度计算的能力,通常采用分布式节点进行AI训练,分布式AI训练性能可以用加速比(scaling efficiency)来衡量,其中加速比指N个节点整体性能相对单个节点性能乘以N倍的百分比。
场景上主要有以下特点:
- 分布式AI训练每轮迭代同步结果时的流量模型为“N对1”的Incast流量,每个迭代期间的突发流量数量和参数量大小正相关。随着计算能力和存储性能的提高,使得AI训练的压力激增,网络设备对Incast流量的承受度也需要提高。
- AI场景对计算性能要求很高,主要使用GPU芯片甚至专门的AI芯片进行计算,服务器规模相对较小。
- 大规模场景下,分布式AI训练性能受限于网络传输次数和时延,需要处理好吞吐(带宽)和时延之间的权衡,通过提高吞吐和降低时延保证加速比。
混合场景
AI Fabric也支持应用在以下混合场景:
- 高性能计算与分布式存储系统同时部署的场景。
- 人工智能与分布式存储系统同时部署的场景。
此时根据实际部署的应用,同一个场景中,服务器使用25GE或100GE接入Leaf交换机,建议Leaf节点部署同时支持25GE和100GE接口类型的交换机。
来源
https://support.huawei.com/enterprise/zh/doc/EDOC1100198639/a6e647e0